A 股申万行业轮动规律
基于申万一级行业指数,量化分析 27 个行业在 2021-2024 年不同市场环境下的超额收益规律。试图回答一个具体问题:在不同的市场环境下,该买哪类行业、避开哪类行业?
本项目的代码与分析框架由 AI 协助构建,作为我学习量化数据分析流程的实践材料。当前展示的是项目的完整流程与结论,每一步背后的原理与代码逻辑正在逐步深入理解,学习笔记会在下方持续补充。
项目定位
project scope
项目背景数字
先把项目的样本规模、时间范围、市场环境分布讲清楚,后续所有结论都建立在这套数据基础之上。
methodology
分析流程四步
从原始数据到结构化结论的完整链路。每一步对应一个明确的分析目的,组合起来才是行业轮动分析。
通过 AkShare 拉取沪深 300 与申万一级 27 个行业指数日线数据,覆盖 2021-2024 年共 938 个交易日。沪深 300 作为基准,申万行业作为分析对象。
用沪深 300 的 20 日滚动收益作为分类信号:> 5% 标记为上涨期,< -5% 为下跌期,其余为震荡期。这一步把每个交易日打上环境标签,是后续分组分析的前提。
超额收益 = 行业日涨跌幅 - 沪深 300 日涨跌幅。这个指标剥离市场整体走势,回答的是行业相对于市场的强弱,而不是行业自身涨跌。
按 行业 × 市场环境 双维度分组,输出三个核心指标:平均超额收益(弹性)、胜率(持续性)、样本数(稳健性)。三个指标互补,单独看任一个都会失真。
findings
四条核心发现
按行业类型分组,每条发现都对应特定环境下的策略含义。第三条反常识发现是这个项目最值得展开的部分。
上涨期弹性最大,但回撤同样放大
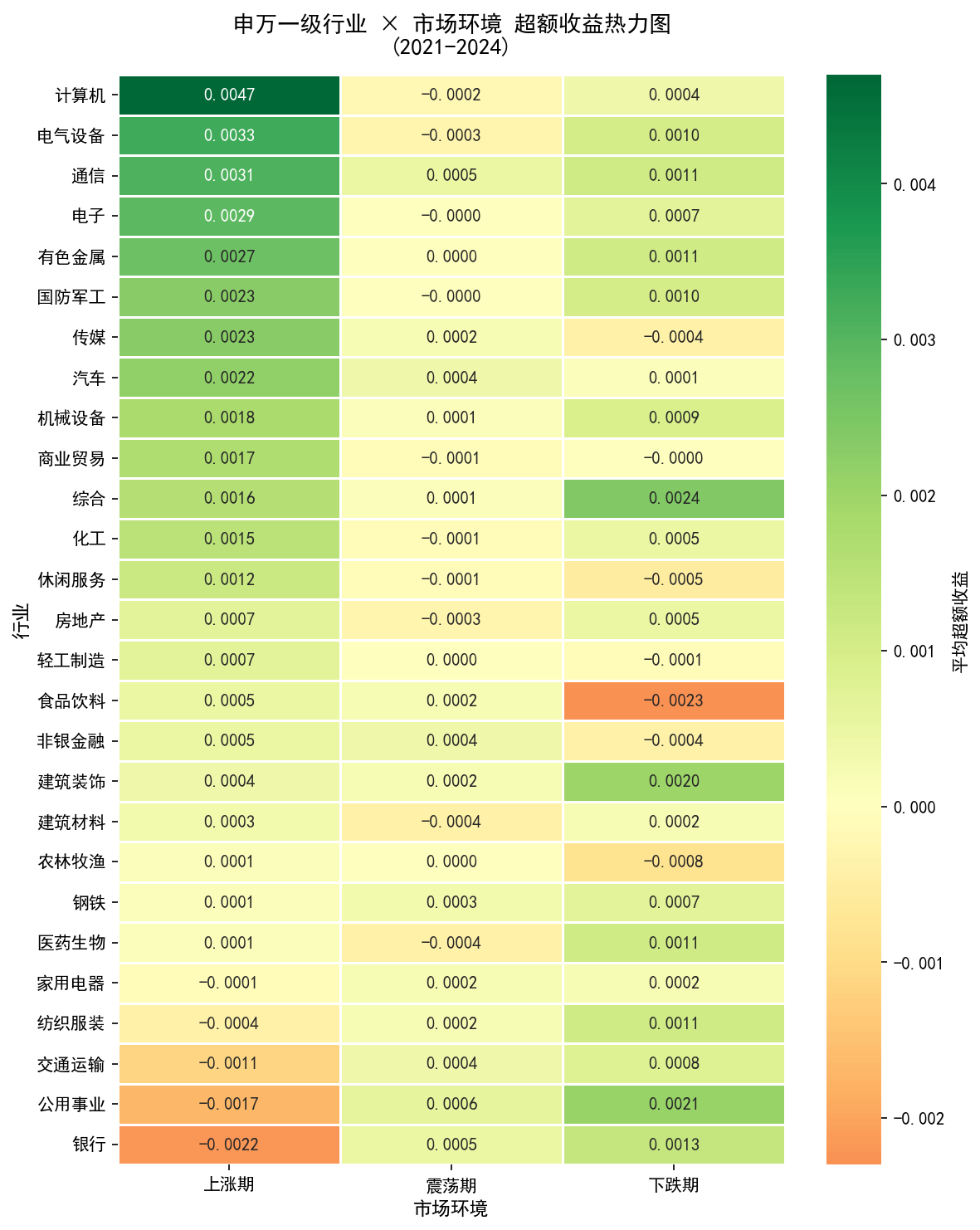
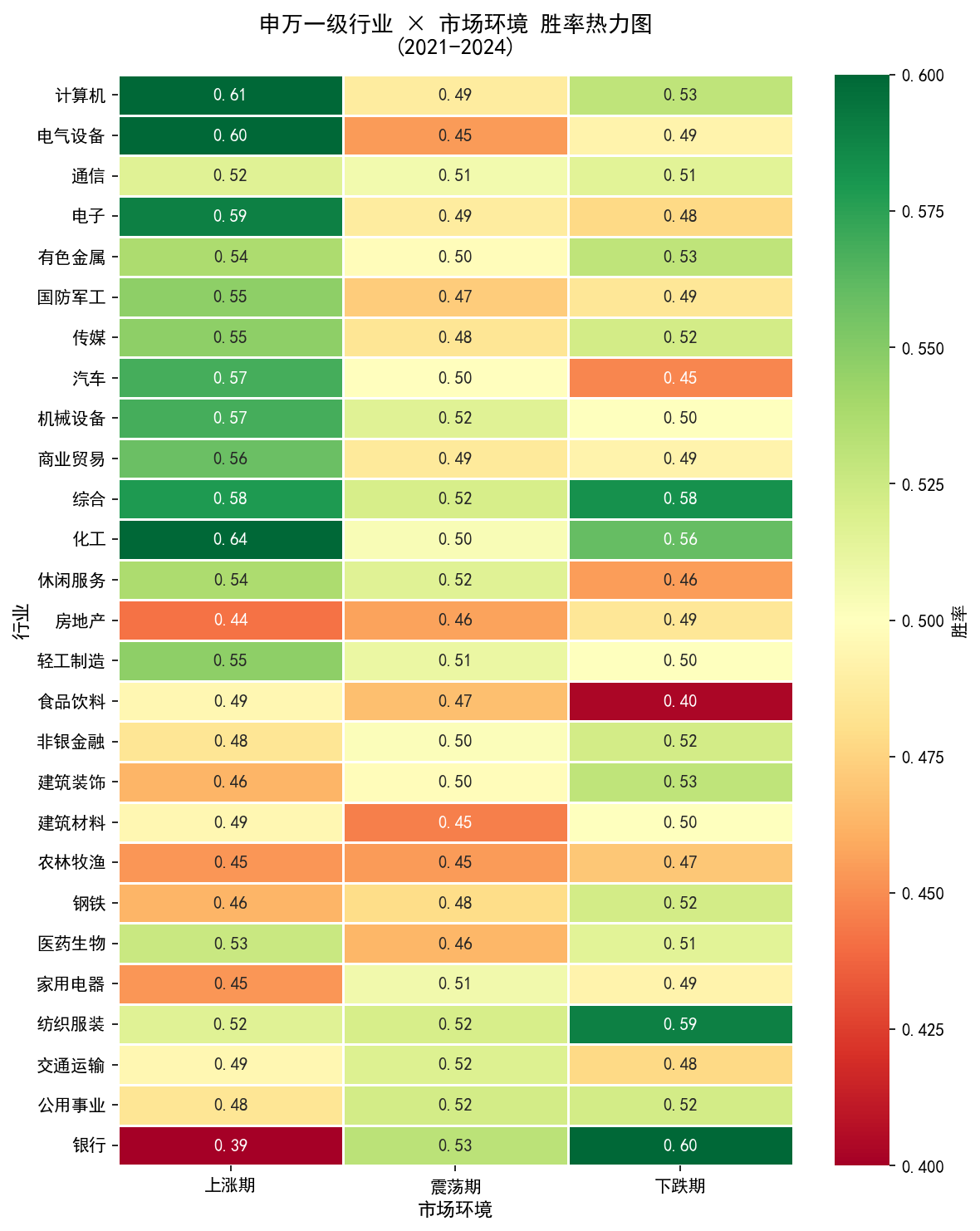
计算机、电气设备、电子在上涨期日均超额收益分别为 +0.47%、+0.33%、+0.29%,胜率达 61%、60%、59%。但下跌期超额收益转负,β 值高、涨跌均放大,适合趋势明确的上涨期持有。
银行是最纯粹的防御行业
银行上涨期胜率仅 0.39(27 个行业最低),下跌期胜率 0.60(最高),与市场走势呈明显负相关。2021-2024 累计收益虽跑输大盘,但在 2022 年熊市中相对抗跌,具备典型防御配置价值。
消费类并非天然防御
食品饮料下跌期日均超额收益 -0.23%、胜率仅 0.40,是下跌期表现最差的行业之一。这与消费等于防御的传统认知相悖。原因可能在于 2021 年白酒高估值叠加消费降级预期,估值杀跌主导了行情,基本面逻辑让位于资金面逻辑。
胜在持续性而非弹性
化工在上涨期胜率 0.64(最高),但单日超额收益中位数低于成长类。2021 年碳中和行情驱动周期类累计涨幅一度超 40%,随后随大宗商品周期回落震荡下行。
visualization
行业 × 环境双维度热力图
超额收益与胜率两张图对照看:前者反映弹性强弱,后者反映持续性。两者结合才能区分行业在不同环境下的真实表现。
超额收益热力图
27 个行业 × 3 种市场环境的平均日超额收益矩阵。颜色越红表示该行业在该环境下相对市场越强,越蓝表示越弱。能直观看到成长类在上涨期、银行在下跌期的红色区块。
胜率热力图
同样的双维度分组,但指标换成胜率(超额收益 > 0 的天数占比)。与超额收益热力图对照看,能区分胜在弹性的行业与胜在持续性的行业。
code highlight
关键代码片段
网页中只展开 1 段最能体现分析能力的核心代码:把日度数据按 行业 × 市场环境 双维度聚合。完整 notebook 保留在 GitHub 仓库中。
alpha_aggregation.py · 行业 × 市场环境双维度聚合
把日度数据按行业和市场环境分组,输出平均超额收益、胜率、样本数三个指标。这是整个分析的核心一步,把日级波动压缩成业务层面的结构化结论。
# 把沪深300日涨跌幅合并进来,用于计算超额收益
df_hs300_ret = df_hs300[['日期', '日涨跌幅']].rename(
columns={'日涨跌幅': '沪深300涨跌幅'}
)
df_merged = pd.merge(df_merged, df_hs300_ret, on='日期', how='inner')
# 超额收益 = 行业日涨跌幅 - 沪深300日涨跌幅
df_merged['超额收益'] = df_merged['日涨跌幅'] - df_merged['沪深300涨跌幅']
# 按 行业 × 市场环境 双维度分组聚合
df_alpha = df_merged.groupby(['行业名称', '市场环境']).agg(
平均超额收益=('超额收益', 'mean'),
胜率=('超额收益', lambda x: (x > 0).mean()),
样本数=('超额收益', 'count')
).round(4).reset_index()
# 输出:27 个行业 × 3 种环境 = 81 条分组记录
# 三个指标互补:
# 平均超额收益 → 弹性
# 胜率 → 持续性
# 样本数 → 稳健性参考learning notes
理解笔记 · 待深入
这些是我目前还没完全吃透的概念,按主题分类,会随学习进度持续更新。
future work
可能的深入方向
这个课题可以进一步展开的方向,作为后续选课题的参考清单,会根据学习进度选择性深入。
project value
项目价值
本项目是我学习量化数据分析流程的实践材料,覆盖从数据获取、市场环境特征工程、超额收益计算到双维度分组聚合的完整链路。重点不在于产出多少创新结论,而在于熟悉一套可复用的分析框架,并对学习过程保持诚实记录。后续会按理解笔记和深入方向逐步补全自己对每一步原理的掌握。