Job Hunter 求职自动化工具
用工程手段解决自己的真实问题:Playwright 抓取职位数据,LLM 对照个人简历数据库逐条打分并给出投递建议,Streamlit 看板完成筛选与投递追踪。从 0 到可用产品单日完成。
项目定位
key results
核心结果一览
从数据规模、LLM 输出结构,到工程上的断点续跑与开发效率,快速定位关键数字。
architecture
三段式 pipeline
采集、分析、呈现三个模块解耦,各自可独立运行:scraper 只管把数据落盘,analyzer 只处理未评分记录,dashboard 只读结果并写回投递状态。
Playwright 驱动 Chromium 抓取实习僧职位,列表页提取基础字段后逐条进入详情页解析工作内容与岗位要求。按链接去重实现增量抓取,随机延时降低被识别风险。单次抓取 923 条。
把个人简历数据库(技能、项目、证书竞赛等核心信息)和每条 JD 拼成 prompt,调用 DeepSeek API 强制 JSON 输出四个字段:匹配度评分、优势、差距、一句话投递建议。每 10 条增量落盘,已分析记录自动跳过,支持中断续跑。
Streamlit 看板呈现全量结果:顶部汇总指标(总职位数、已投递、约面数、平均匹配度),城市、匹配度区间、投递状态三维筛选,点击职位展开优势/差距详情,投递状态修改后直接写回数据文件。
design decisions
关键设计决策
Prompt 设计:system prompt 中明确约定输出 JSON schema(score/strengths/gaps/recommendation),并配合 API 的 response_format=json_object 双保险,避免自然语言混入导致解析失败。
鲁棒性设计:爬虫侧用选择器多级回退(CSS 选择器找不到卡片时降级为 JS 扫描职位链接向上找容器),分析侧单条失败不中断 pipeline——异常记录标记后继续,下次运行自动重试。
增量与幂等:抓取按链接去重,分析每 10 条落盘、重跑跳过已有评分。900+ 条 × 每条 1 秒限速的长任务里,这两个设计让中断成本接近于零。
工具选型:开发用 Claude Code(效率优先),批量打分用 DeepSeek API(900+ 次调用,成本优先),爬虫用 Playwright 而非 requests(目标站动态渲染,requests 拿不到完整 DOM)。按场景选型而不是一把梭。
上线后筛选 JD 的方式从「逐条人工阅读」变成「按匹配度排序 + 读推荐语」,单批 900+ 条职位的初筛时间从数小时压缩到分钟级。LLM 给出的差距分析(gaps 字段)同时反向输出了技能补强清单。
dashboard
求职追踪看板
汇总指标 + 三维筛选 + 投递状态管理
顶部展示总职位数、已投递、约面数与平均匹配度;下方表格支持按城市、匹配度区间、投递状态筛选,每条记录附 LLM 推荐语,投递状态修改后直接写回数据文件。
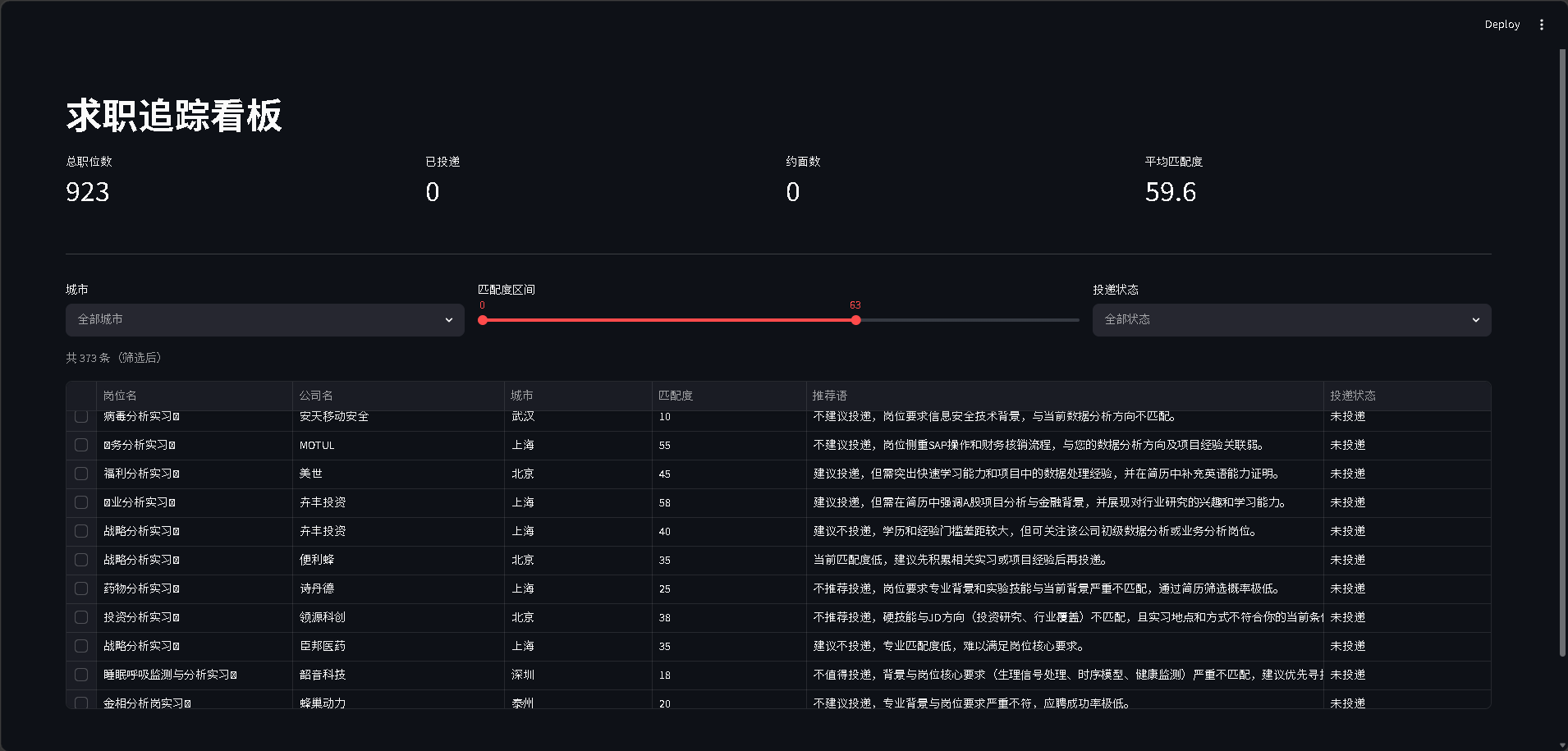
可在线体验完整看板(脱敏抽样数据,88 条)
打开看板code highlight
关键代码片段
展示 LLM 打分的核心实现。完整三模块代码(scraper、analyzer、dashboard)见 GitHub 仓库。
analyzer.py · LLM 结构化打分
核心打分函数:把个人背景和 JD 拼成 prompt,强制 JSON 输出,解析为四个结构化字段。配合主循环的异常捕获与增量落盘,构成可中断、可续跑的批量分析 pipeline。
SYSTEM_PROMPT = (
"你是一个求职顾问,擅长分析候选人与职位的匹配程度。"
"用户会提供个人背景和一条职位JD,请输出JSON格式分析,包含4个字段:\n"
"- score: 整数 0-100,匹配度评分\n"
"- strengths: 字符串,我有哪些符合该职位的经历/技能\n"
"- gaps: 字符串,JD要求但我目前缺乏的能力或经验\n"
"- recommendation: 字符串,一句话说明值不值得投递\n"
"只输出JSON,不要有其他内容。"
)
def call_api(profile, job_content, job_requirements, api_key):
user_msg = (
f"## 我的背景\n{profile}\n\n"
f"## 工作内容\n{job_content}\n\n"
f"## 岗位要求\n{job_requirements}"
)
resp = requests.post(
API_URL,
headers={"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"},
json={
"model": MODEL,
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_msg},
],
# 强制 JSON 输出,避免自然语言混入导致解析失败
"response_format": {"type": "json_object"},
"max_tokens": 800,
},
timeout=30,
)
resp.raise_for_status()
data = json.loads(resp.json()["choices"][0]["message"]["content"])
return (
int(data.get("score", 0)),
str(data.get("strengths", "未获取")),
str(data.get("gaps", "未获取")),
str(data.get("recommendation", "未获取")),
)data
数据与技术细节
limitations
局限性与迭代方向
project value
项目价值
与另外两个分析项目不同,本项目体现的是工程落地能力:识别真实痛点、设计三段式 pipeline、用 LLM 结构化输出解决非结构化文本的批量评估问题,并在浏览器自动化、异常处理、断点续跑等工程细节上做出取舍。AI 工具(Claude Code 开发 + DeepSeek 打分)按场景选型而非盲目堆砌,是数据分析师在 AI 时代工作方式的一个具体样本。