Olist 电商分析
从经营全貌到取消风险建模的两阶段分析。SQL 完成多表关联与指标提取,Power BI 完成可视化,统计建模验证支付方式与金额的交互效应。
项目结构
summary_kpi
核心指标总览
首页用于快速判断平台经营表现,按规模到订单到单价到用户到质量到履约的顺序展示关键指标。
核心经营结论
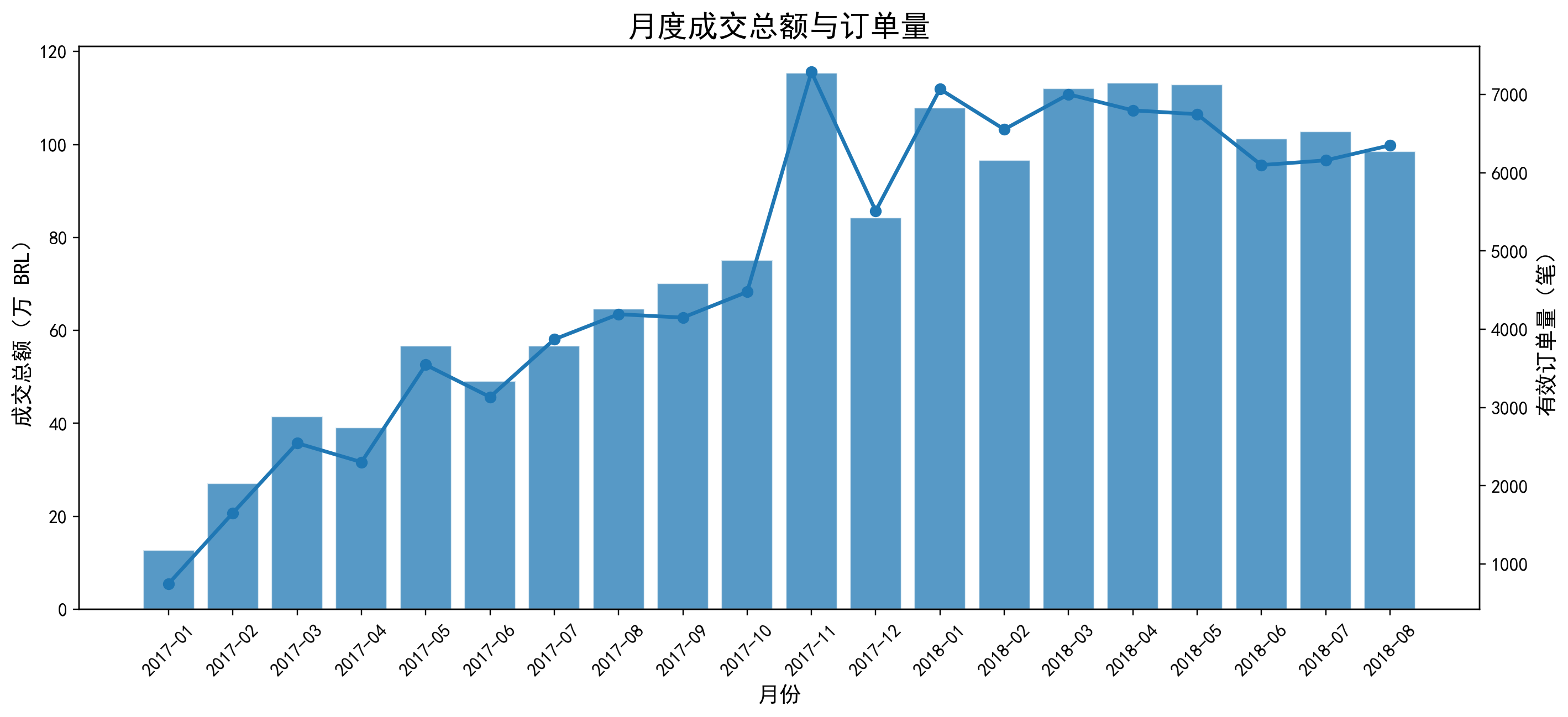
平台成交规模在 2017 年进入明显爬坡期,2017-11 至 2018-05 进入高位运行区间。其中 2017-11 成交总额达到 115.35 万,为样本期单月峰值;2018-03 至 2018-05 连续三个月保持在 112 万左右,说明平台在后期已形成较稳定的高交易体量。
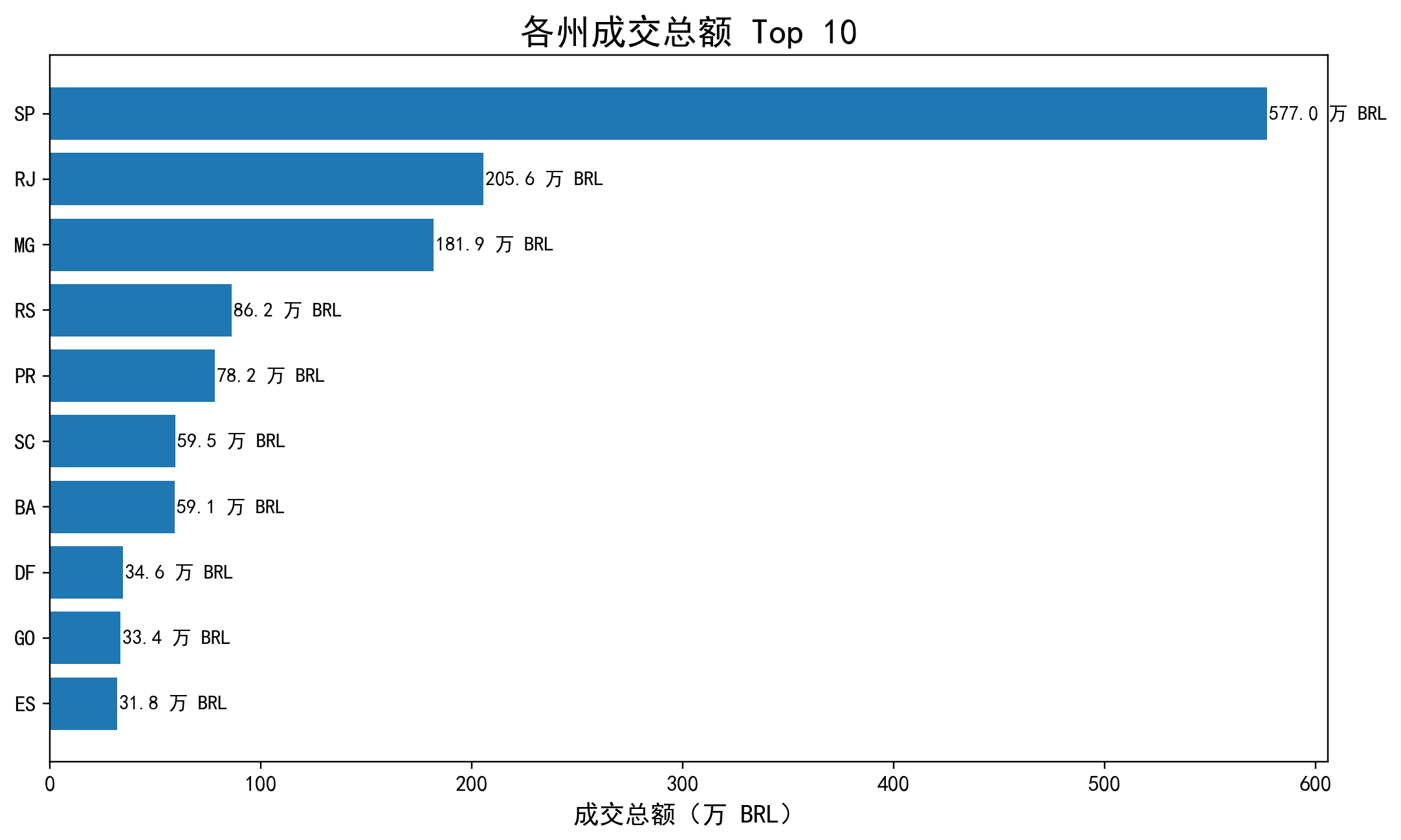
区域表现呈现出明显的规模核心区 + 高客单外围区结构。SP 以 577.03 万成交总额和 4.05 万有效订单绝对领先,但客单价仅 142.48,明显低于 PA、PB、AL 等低订单量高客单价州,说明头部州主要靠订单规模驱动,部分长尾州则更依赖单笔金额支撑。
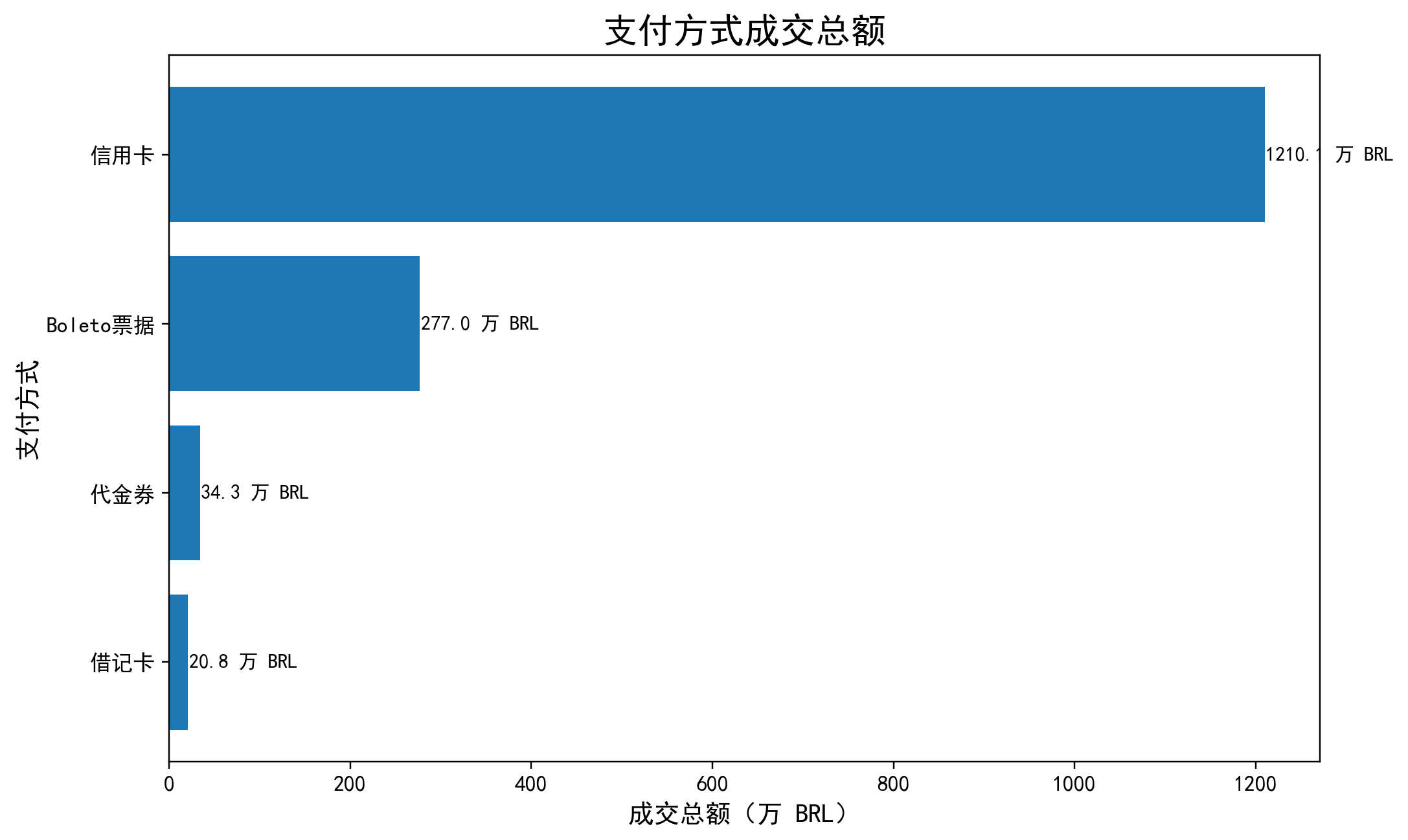
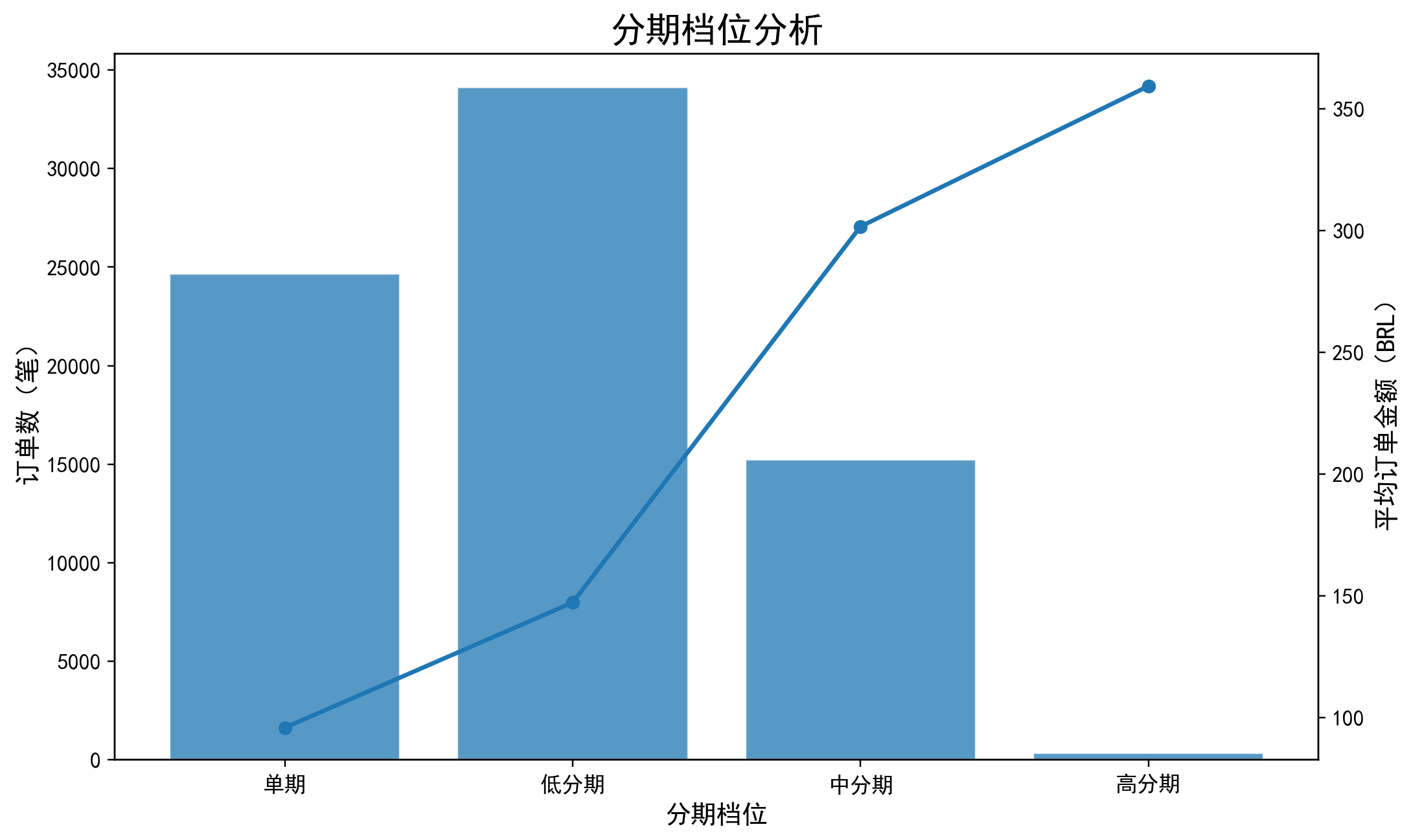
支付与分期结构揭示出较清晰的消费分层:credit_card 贡献 1210.11 万成交总额,占主导地位;而信用卡订单中,单期平均订单金额仅 95.92,2-5 期提升至 147.33,6-10 期进一步升至 301.74,10 期以上达到 359.40,表明高金额订单明显更依赖中高分期完成支付。
整体订单完成质量较稳,终态失败率仅 1.26%,但履约效率存在显著区域差异。SP 平均配送天数仅 8.7 天,而 RR、AP、AM 等州已达到 29.34、27.18、26.36 天,说明平台在全国扩展后,远距离与低密度区域的物流效率明显弱于核心市场。
dashboard
Power BI 仪表板展示
KPI 总览页
展示成交总额、有效订单量、平均客单价、去重买家数、终态失败率与平均配送天数,用于快速判断平台整体规模、订单质量与履约效率。当前首页指标显示:成交总额约 R$ 1542 万,终态失败率仅 1.26%,平均配送天数为 12.5 天。

月度成交额与订单量
按月展示成交总额与有效订单量变化,用于识别平台增长阶段与波动区间。结果显示 2017-11 为单月成交峰值,2018-03 至 2018-05 维持高位运行,说明后期交易规模趋于稳定。
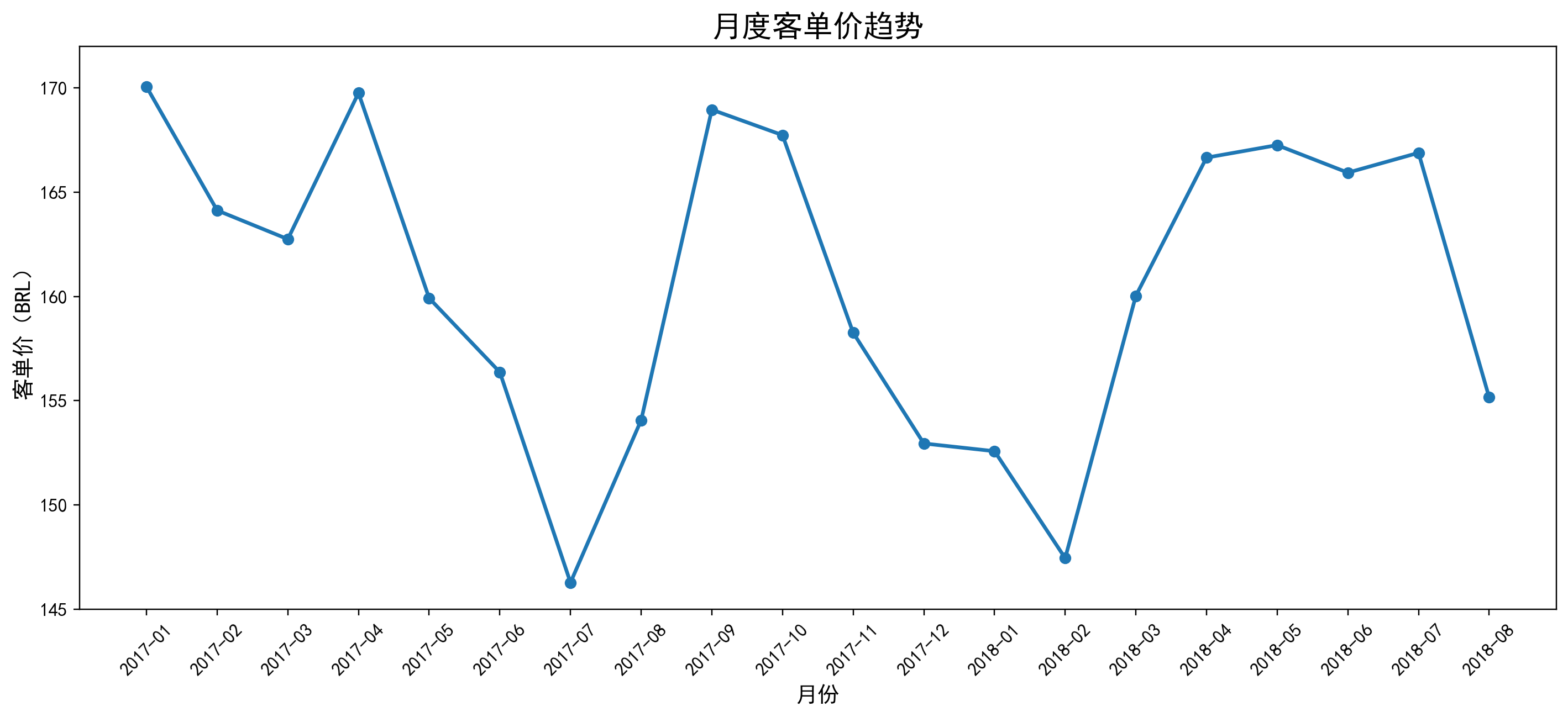
月度客单价趋势
展示主业务阶段的月度客单价变化,用于观察订单质量与价格结构是否稳定,并辅助判断成交规模波动是由订单量还是单价主导。
各州成交总额 Top 10
展示成交总额排名前 10 的州,用于识别核心贡献地区与区域集中度。结合州维度表现可见,SP、RJ、MG 是最主要的交易贡献区域。
支付方式成交总额
展示不同支付方式对应的成交总额,用于识别主导支付方式及支付结构差异。结果显示 credit_card 是最核心的支付路径。
分期档位分析
展示不同分期档位下的订单数与平均订单金额,用于观察信用卡分期结构与高金额订单特征。结果显示平均订单金额随分期数上升而显著抬升。
metrics
指标口径说明
challenge
项目难点与处理
sql directory
SQL 模块目录
按 GitHub 中的实际 SQL 文件拆分展示用途与入口。完整代码放在 GitHub 仓库中。
用于完成数据预览、时间窗口确认、订单状态分布检查,以及州维度订单量与终态失败率摸底。
用于输出核心经营指标、月度经营趋势,并补充支付方式与信用卡分期结构分析。
用于完成区域分析、履约分析,以及三表合并后的区域经营质量对比。
用于生成 summary_kpi 页的一行总览数据,包含成交总额、有效订单量、客单价、买家数、终态失败率与平均配送天数。
用于生成月度趋势页数据,按月份输出成交总额、有效订单量与客单价。
用于生成州表现页数据,综合输出客户州的成交、订单、客单价、终态失败率与配送时长。
用于生成支付方式页数据,比较不同支付方式下的订单量、成交总额与客单价。
用于生成分期分析页数据,比较不同信用卡分期档位下的订单数与平均订单金额。
sql highlight
关键 SQL 示例
网页中只展开 1 段最能体现项目能力的重点 SQL,其余文件保留在 GitHub 仓库中。
11_summary_kpi.sql · 首页总览指标
通过交易、买家、终态失败率与配送天数四组指标,汇总成 summary_kpi 页的一行结果。
with payment_agg as (
select
order_id,
sum(payment_value) as payment_value
from olist_order_payments_dataset
group by order_id
),
trade_kpi as (
select
round(sum(p.payment_value), 2) as gmv,
count(distinct o.order_id) as valid_order_cnt,
round(sum(p.payment_value) / count(distinct o.order_id), 2) as aov
from olist_orders_dataset o
join payment_agg p on o.order_id = p.order_id
where o.order_status = 'delivered'
),
customer_kpi as (
select count(distinct c.customer_unique_id) as unique_customer_cnt
from olist_orders_dataset o
join olist_customers_dataset c on o.customer_id = c.customer_id
where o.order_status = 'delivered'
),
fail_kpi as (
select round(sum(order_status in ('canceled', 'unavailable')) / count(*) * 100, 2) as fail_rate_pct
from olist_orders_dataset
where order_status in ('delivered', 'canceled', 'unavailable')
),
delivery_kpi as (
select round(avg(datediff(order_delivered_customer_date, order_purchase_timestamp)), 2) as avg_delivery_days
from olist_orders_dataset
where order_status = 'delivered'
and order_delivered_customer_date is not null
and order_purchase_timestamp is not null
)
select
t.gmv as '成交总额',
t.valid_order_cnt as '有效订单量',
t.aov as '客单价',
c.unique_customer_cnt as '去重买家数',
f.fail_rate_pct as '终态失败率',
d.avg_delivery_days as '平均配送天数'
from trade_kpi t
cross join customer_kpi c
cross join fail_kpi f
cross join delivery_kpi d;model results
核心建模结果
三层分析的核心数字一览:从样本规模、类别不平衡,到 Fisher 检验、独立效应、交互项放大效应。
methodology
三层分析路径
不同精度的问题用不同方法回答。三层依次回答信号是否存在、控制变量后是否仍显著、组合是否产生超线性放大。
高价区间 Voucher 样本仅 75 条,大样本卡方近似不再可靠,改用 Fisher 精确检验避免假设失效。直接比较两种支付方式的取消率差异,回答信号是否存在。
特征:is_voucher、payment_value。在全量数据上估计两者各自的独立效应,回答控制金额后 Voucher 效应是否仍显著,排除 Voucher 取消率高仅因金额高的混淆假设。
用交互项捕捉高金额 + Voucher 是否存在超出单独效应的组合放大。statsmodels Logit 拟合,输出系数、p 值、95% CI,并用 AIC 对比基础模型判断是否为有效信息。
findings
三层分析的核心结论
Fisher 精确检验:300+ 区间 Voucher 取消率 20.00%(15/75),信用卡仅 0.79%(65/8268),Odds Ratio 31.55,p < 0.000001。差异不可能由抽样波动解释,高价区间确实存在 Voucher 异常风险。
基础逻辑回归:在全量数据上控制金额后,Voucher 支付本身仍独立提升取消概率约 39%(OR=1.39,95% CI [1.33, 1.45]),金额每升高一个标准差额外提升约 15%(OR=1.15)。两个效应都不被对方解释掉,排除混淆假设。
交互项逻辑回归:voucher × payment_value 交互项 OR=1.09,95% CI [1.06, 1.13],p < 0.0001。模型 AIC 从 6083 降至 6049,加入交互项是有效信息而非噪声。在 Voucher 用户中,金额对取消率的放大作用比信用卡用户更强,组合风险并非简单叠加。
三层互相印证:高价区间的极端差异(Fisher OR=31.55)在全量数据上被分解为支付方式独立效应、金额独立效应、组合放大效应三个分量,且都在统计上显著。从描述性发现到因果验证的链路完整闭合。
visualization
交互项模型 Odds Ratio
展示三个特征的 OR 及 95% 置信区间。voucher × payment_value 交互项橙色高亮,红色虚线为 OR=1 的 baseline。三个 OR 均显著大于 1,且交互项不被两个独立效应吸收。
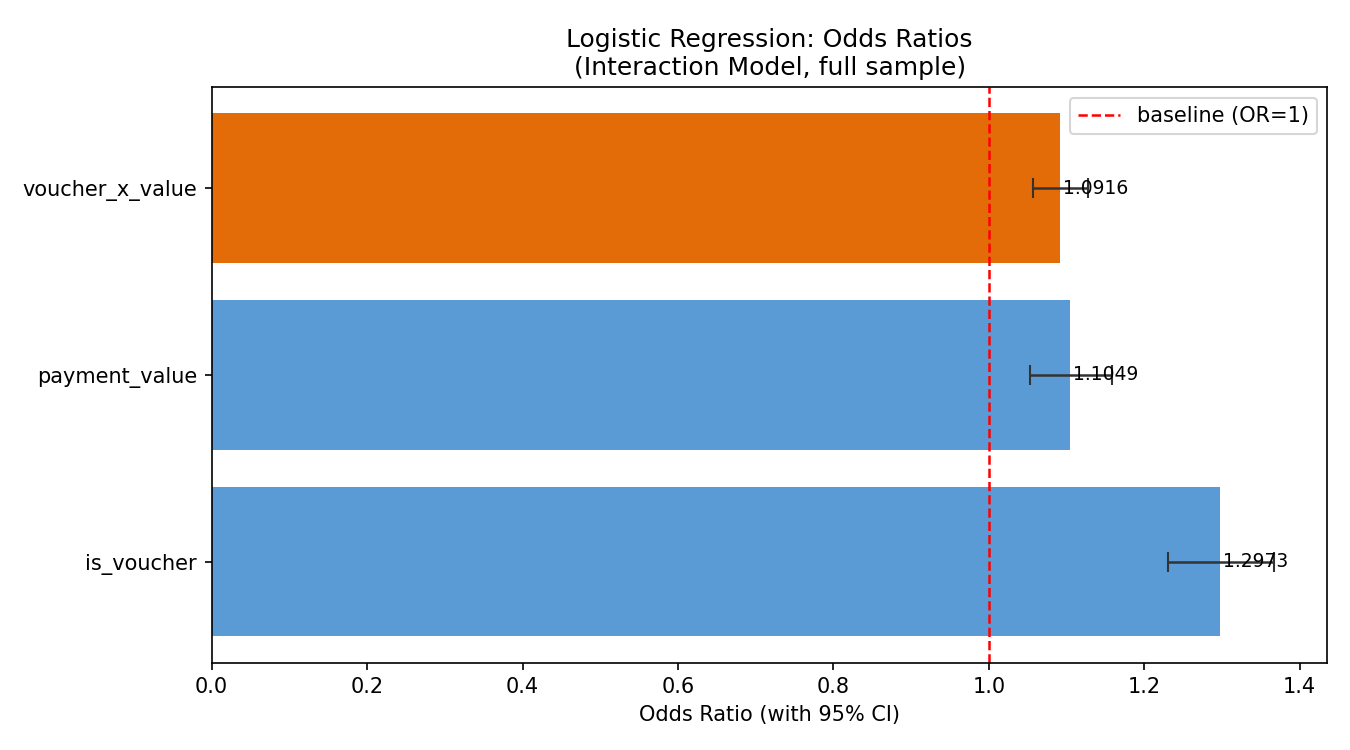
交互项 OR=1.09 看似不大,但需要结合两点理解:一是已经控制了 Voucher 与金额的独立效应,交互项捕捉的是两者之外的额外放大;二是 AIC 从 6083 降至 6049 说明加入交互项是有效信息而非噪声。换言之,高金额 + Voucher 的风险组合不是两者风险的简单叠加。
code highlight
关键代码片段
网页中只展开 1 段最能体现项目能力的建模代码,完整三层分析代码保留在 GitHub 仓库中。
interaction_logit.py · 交互项逻辑回归
用 statsmodels Logit 拟合含交互项的逻辑回归,输出 OR 与 95% 置信区间。交互项的显著性是验证高金额 + Voucher 组合放大效应的关键。
# 第六部分:交互项逻辑回归
features_inter = ['is_voucher', 'payment_value', 'voucher_x_value']
scaler_inter = StandardScaler()
X_inter = scaler_inter.fit_transform(df[features_inter])
X_inter = sm.add_constant(X_inter)
model_inter = sm.Logit(y, X_inter).fit(disp=0)
# 提取 OR 与 95% CI
print("Odds Ratio(交互项模型):")
pvals_inter = model_inter.pvalues.values[1:]
for name, coef, (lo, hi), p in zip(
features_inter,
model_inter.params[1:],
model_inter.conf_int().iloc[1:].values,
pvals_inter
):
print(f" {name:20s} OR={np.exp(coef):.4f} "
f"95%CI=[{np.exp(lo):.4f}, {np.exp(hi):.4f}] "
f"p={p:.4f}")
# 输出:
# is_voucher OR=1.30 95%CI=[1.23, 1.37] p<0.0001
# payment_value OR=1.10 95%CI=[1.05, 1.16] p<0.0001
# voucher_x_value OR=1.09 95%CI=[1.06, 1.13] p<0.0001
# AIC: 6083 → 6049(基础模型 vs 交互项模型)challenge
建模难点与处理
business action
业务建议
data
数据与样本
limitations
局限性
project value
项目价值
本项目覆盖了从业务问题拆解、SQL 多表关联与指标提取、Power BI 可视化展示,到描述性发现驱动建模、混淆假设识别与控制、交互项验证组合效应的完整分析链路。两个阶段构成从"经营全貌"到"因果验证"的闭环,重点体现数据口径意识、统计方法选择能力与建模结论解释能力。